The expression of numerical quantities is something we tend to take for granted. This is both a good and a bad thing in the study of electronics. It is good, in that we're accustomed to the use and manipulation of numbers for the many calculations used in analyzing electronic circuits. On the other hand, the particular system of notation we've been taught from grade school onward is not the system used internally in modern electronic computing devices, and learning any different system of notation requires some re-examination of deeply ingrained assumptions.
First, we have to distinguish the difference between numbers and the symbols we use to represent numbers. A number is a mathematical quantity, usually correlated in electronics to a physical quantity such as voltage, current, or resistance. There are many different types of numbers. Here are just a few types, for example:
WHOLE NUMBERS:
1, 2, 3, 4, 5, 6, 7, 8, 9 . . .
INTEGERS:
-4, -3, -2, -1, 0, 1, 2, 3, 4 . . .
IRRATIONAL NUMBERS:
π (approx. 3.1415927), e (approx. 2.718281828),
square root of any prime
REAL NUMBERS:
(All one-dimensional numerical values, negative and positive,
including zero, whole, integer, and irrational numbers)
COMPLEX NUMBERS:
3 - j4 , 34.5 ∠ 20o
Different types of numbers find different application in the physical world. Whole numbers work well for counting discrete objects, such as the number of resistors in a circuit. Integers are needed when negative equivalents of whole numbers are required. Irrational numbers are numbers that cannot be exactly expressed as the ratio of two integers, and the ratio of a perfect circle's circumference to its diameter (π) is a good physical example of this. The non-integer quantities of voltage, current, and resistance that we're used to dealing with in DC circuits can be expressed as real numbers, in either fractional or decimal form. For AC circuit analysis, however, real numbers fail to capture the dual essence of magnitude and phase angle, and so we turn to the use of complex numbers in either rectangular or polar form.
If we are to use numbers to understand processes in the physical world, make scientific predictions, or balance our checkbooks, we must have a way of symbolically denoting them. In other words, we may know how much money we have in our checking account, but to keep record of it we need to have some system worked out to symbolize that quantity on paper, or in some other kind of form for record-keeping and tracking. There are two basic ways we can do this: analog and digital. With analog representation, the quantity is symbolized in a way that is infinitely divisible. With digital representation, the quantity is symbolized in a way that is discretely packaged.
You're probably already familiar with an analog representation of money, and didn't realize it for what it was. Have you ever seen a fund-raising poster made with a picture of a thermometer on it, where the height of the red column indicated the amount of money collected for the cause? The more money collected, the taller the column of red ink on the poster.
Systems of numerationThe Romans devised a system that was a substantial improvement over hash marks, because it used a variety of symbols (or ciphers) to represent increasingly large quantities. The notation for 1 is the capital letter I. The notation for 5 is the capital letter V. Other ciphers possess increasing values:
X = 10
L = 50
C = 100
D = 500
M = 1000
If a cipher is accompanied by another cipher of equal or lesser value to the immediate right of it, with no ciphers greater than that other cipher to the right of that other cipher, that other cipher's value is added to the total quantity. Thus, VIII symbolizes the number 8, and CLVII symbolizes the number 157. On the other hand, if a cipher is accompanied by another cipher of lesser value to the immediate left, that other cipher's value is subtracted from the first. Therefore, IV symbolizes the number 4 (V minus I), and CM symbolizes the number 900 (M minus C). You might have noticed that ending credit sequences for most motion pictures contain a notice for the date of production, in Roman numerals. For the year 1987, it would read: MCMLXXXVII. Let's break this numeral down into its constituent parts, from left to right:
M = 1000
+
CM = 900
+
L = 50
+
XXX = 30
+
V = 5
+
II = 2
Aren't you glad we don't use this system of numeration? Large numbers are very difficult to denote this way, and the left vs. right / subtraction vs. addition of values can be very confusing, too. Another major problem with this system is that there is no provision for representing the number zero or negative numbers, both very important concepts in mathematics. Roman culture, however, was more pragmatic with respect to mathematics than most, choosing only to develop their numeration system as far as it was necessary for use in daily life.
We owe one of the most important ideas in numeration to the ancient Babylonians, who were the first (as far as we know) to develop the concept of cipher position, or place value, in representing larger numbers. Instead of inventing new ciphers to represent larger numbers, as the Romans did, they re-used the same ciphers, placing them in different positions from right to left. Our own decimal numeration system uses this concept, with only ten ciphers (0, 1, 2, 3, 4, 5, 6, 7, 8, and 9) used in "weighted" positions to represent very large and very small numbers.
Each cipher represents an integer quantity, and each place from right to left in the notation represents a multiplying constant, or weight, for each integer quantity. For example, if we see the decimal notation "1206", we known that this may be broken down into its constituent weight-products as such:
1206 = 1000 + 200 + 6
1206 = (1 x 1000) + (2 x 100) + (0 x 10) + (6 x 1)
Each cipher is called a digit in the decimal numeration system, and each weight, or place value, is ten times that of the one to the immediate right. So, we have a ones place, a tens place, a hundreds place, a thousands place, and so on, working from right to left.
Right about now, you're probably wondering why I'm laboring to describe the obvious. Who needs to be told how decimal numeration works, after you've studied math as advanced as algebra and trigonometry? The reason is to better understand other numeration systems, by first knowing the how's and why's of the one you're already used to.
The decimal numeration system uses ten ciphers, and place-weights that are multiples of ten. What if we made a numeration system with the same strategy of weighted places, except with fewer or more ciphers?
The binary numeration system is such a system. Instead of ten different cipher symbols, with each weight constant being ten times the one before it, we only have two cipher symbols, and each weight constant is twice as much as the one before it. The two allowable cipher symbols for the binary system of numeration are "1" and "0," and these ciphers are arranged right-to-left in doubling values of weight. The rightmost place is the ones place, just as with decimal notation. Proceeding to the left, we have the twos place, the fours place, the eights place, the sixteens place, and so on. For example, the following binary number can be expressed, just like the decimal number 1206, as a sum of each cipher value times its respective weight constant:
11010 = 2 + 8 + 16 = 26
11010 = (1 x 16) + (1 x 8) + (0 x 4) + (1 x 2) + (0 x 1)
This can get quite confusing, as I've written a number with binary numeration (11010), and then shown its place values and total in standard, decimal numeration form (16 + 8 + 2 = 26). In the above example, we're mixing two different kinds of numerical notation. To avoid unnecessary confusion, we have to denote which form of numeration we're using when we write (or type!). Typically, this is done in subscript form, with a "2" for binary and a "10" for decimal, so the binary number 110102 is equal to the decimal number 2610.
The subscripts are not mathematical operation symbols like superscripts (exponents) are. All they do is indicate what system of numeration we're using when we write these symbols for other people to read. If you see "310", all this means is the number three written using decimal numeration. However, if you see "310", this means something completely different: three to the tenth power (59,049). As usual, if no subscript is shown, the cipher(s) are assumed to be representing a decimal number.
Commonly, the number of cipher types (and therefore, the place-value multiplier) used in a numeration system is called that system's base. Binary is referred to as "base two" numeration, and decimal as "base ten." Additionally, we refer to each cipher position in binary as a bit rather than the familiar word digit used in the decimal system.
Now, why would anyone use binary numeration? The decimal system, with its ten ciphers, makes a lot of sense, being that we have ten fingers on which to count between our two hands. (It is interesting that some ancient central American cultures used numeration systems with a base of twenty. Presumably, they used both fingers and toes to count!!). But the primary reason that the binary numeration system is used in modern electronic computers is because of the ease of representing two cipher states (0 and 1) electronically. With relatively simple circuitry, we can perform mathematical operations on binary numbers by representing each bit of the numbers by a circuit which is either on (current) or off (no current). Just like the abacus with each rod representing another decimal digit, we simply add more circuits to give us more bits to symbolize larger numbers. Binary numeration also lends itself well to the storage and retrieval of numerical information: on magnetic tape (spots of iron oxide on the tape either being magnetized for a binary "1" or demagnetized for a binary "0"), optical disks (a laser-burned pit in the aluminum foil representing a binary "1" and an unburned spot representing a binary "0"), or a variety of other media types.
Before we go on to learning exactly how all this is done in digital circuitry, we need to become more familiar with binary and other associated systems of numeration.
Decimal versus binary numerationLet's count from zero to twenty using four different kinds of numeration systems: hash marks, Roman numerals, decimal, and binary:
System: Hash Marks Roman Decimal Binary
------- ---------- ----- ------- ------
Zero n/a n/a 0 0
One I 1 1
Two II 2 10
Three III 3 11
Four IV 4 100
Five // V 5 101
Six // VI 6 110
Seven // VII 7 111
Eight // VIII 8 1000
Nine // IX 9 1001
Ten // // X 10 1010
Eleven // // XI 11 1011
Twelve // // XII 12 1100
Thirteen // // XIII 13 1101
Fourteen // // XIV 14 1110
Fifteen // // // XV 15 1111
Sixteen // // // XVI 16 10000
Seventeen // // // XVII 17 10001
Eighteen // // // XVIII 18 10010
Nineteen // // // XIX 19 10011
Twenty // // // // XX 20 10100
Neither hash marks nor the Roman system are very practical for symbolizing large numbers. Obviously, place-weighted systems such as decimal and binary are more efficient for the task. Notice, though, how much shorter decimal notation is over binary notation, for the same number of quantities. What takes five bits in binary notation only takes two digits in decimal notation.
This raises an interesting question regarding different numeration systems: how large of a number can be represented with a limited number of cipher positions, or places? With the crude hash-mark system, the number of places IS the largest number that can be represented, since one hash mark "place" is required for every integer step. For place-weighted systems of numeration, however, the answer is found by taking base of the numeration system (10 for decimal, 2 for binary) and raising it to the power of the number of places. For example, 5 digits in a decimal numeration system can represent 100,000 different integer number values, from 0 to 99,999 (10 to the 5th power = 100,000). 8 bits in a binary numeration system can represent 256 different integer number values, from 0 to 11111111 (binary), or 0 to 255 (decimal), because 2 to the 8th power equals 256. With each additional place position to the number field, the capacity for representing numbers increases by a factor of the base (10 for decimal, 2 for binary).
An interesting footnote for this topic is the one of the first electronic digital computers, the Eniac. The designers of the Eniac chose to represent numbers in decimal form, digitally, using a series of circuits called "ring counters" instead of just going with the binary numeration system, in an effort to minimize the number of circuits required to represent and calculate very large numbers. This approach turned out to be counter-productive, and virtually all digital computers since then have been purely binary in design.
To convert a number in binary numeration to its equivalent in decimal form, all you have to do is calculate the sum of all the products of bits with their respective place-weight constants. To illustrate:
Convert 110011012 to decimal form:
bits = 1 1 0 0 1 1 0 1
. - - - - - - - -
weight = 1 6 3 1 8 4 2 1
(in decimal 2 4 2 6
notation) 8
The bit on the far right side is called the Least Significant Bit (LSB), because it stands in the place of the lowest weight (the one's place). The bit on the far left side is called the Most Significant Bit (MSB), because it stands in the place of the highest weight (the one hundred twenty-eight's place). Remember, a bit value of "1" means that the respective place weight gets added to the total value, and a bit value of "0" means that the respective place weight does not get added to the total value. With the above example, we have:
12810 + 6410 + 810 + 410 + 110 = 20510
If we encounter a binary number with a dot (.), called a "binary point" instead of a decimal point, we follow the same procedure, realizing that each place weight to the right of the point is one-half the value of the one to the left of it (just as each place weight to the right of a decimal point is one-tenth the weight of the one to the left of it). For example:
Convert 101.0112 to decimal form:
.
bits = 1 0 1 . 0 1 1
. - - - - - - -
weight = 4 2 1 1 1 1
(in decimal / / /
notation) 2 4 8
410 + 110 + 0.2510 + 0.12510 = 5.37510

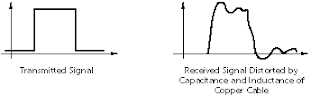 These effects are properties of transmission through metallic conductors, and become more pronounced as the conductor length increases. To compensate for distortion, signal power must be increased or the transmission rate decreased.
These effects are properties of transmission through metallic conductors, and become more pronounced as the conductor length increases. To compensate for distortion, signal power must be increased or the transmission rate decreased.







_thumb%5B2%5D.jpg)
%5B5%5D.jpg)
_thumb%5B2%5D.jpg)
_thumb%5B2%5D.jpg)





